题目
CUDA实现向量加法和矩阵乘法
- 用CUDA实现向量加法的计算
- 定义A,B两个一维数组,编写GPU程序将A和B对应项相加,将结果保存在数组C中。分别测试数组规模为10W、20W、100W、200W、1000W、2000W时其与CPU加法的运行时间之比。
- 用CUDA实现矩阵乘法的计算
- 定义A,B 两个二维数组。使用GPU 实现矩阵乘法。并对比串行程序,给出加速比。
算法设计
向量加法的计算
考虑向量A, B, C, 长度为n,C = A + B
基本的串行算法
使用for循环将A的每个分量加到B的对应分量上得到C的对应分量即可。
CUDA并行算法
每个线程进行一个分量的计算
由于一个Block最多只能有512个线程,因此设置Block的大小BLOCK_SIZE为500(一维,方便计算,另二维默认为1),Grid的大小为 n / BLOCK_SIZE(一维,另一维默认为1)
GPU核函数中,对于每一个线程,记bx = blockIdx.x,tx = threadIdx.x,该线程负责计算i = bx * BLOCK_SIZE + tx下标的向量分量
向量乘法的计算
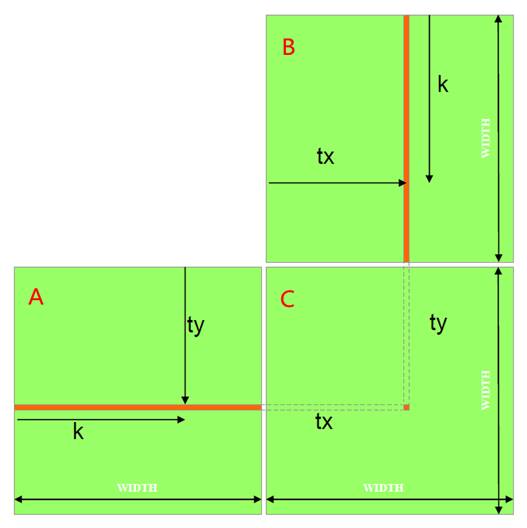
考虑矩阵A, B, C, C = A x B为了,便于说明,假设宽度和高度均为WIDTH,实际编程中将实现长宽不等的矩阵乘法
基本的串行算法
两层for循环,每次计算C矩阵中的一个元素 ,需要A的一行和B的一列,对应元素相乘,进行求和,总共是三层循环。
CUDA并行算法
只使用了一个线程块,一个线程块中的每个线程计算C中的一个元素,每个线程载入矩阵A中的一行,载入矩阵B中的一列,为每对A和B元素执行了一次乘法和加法。
缺点:计算和片外存储器存访问比例接近1:1,受存储器延迟影响很大;矩阵的大小受到线程块所能容纳最大线程数(512个线程)的限制;所有的线程都要访问全局存储器获取输入矩阵元素;每个输入元素都需要被WIDTH个线程读取。
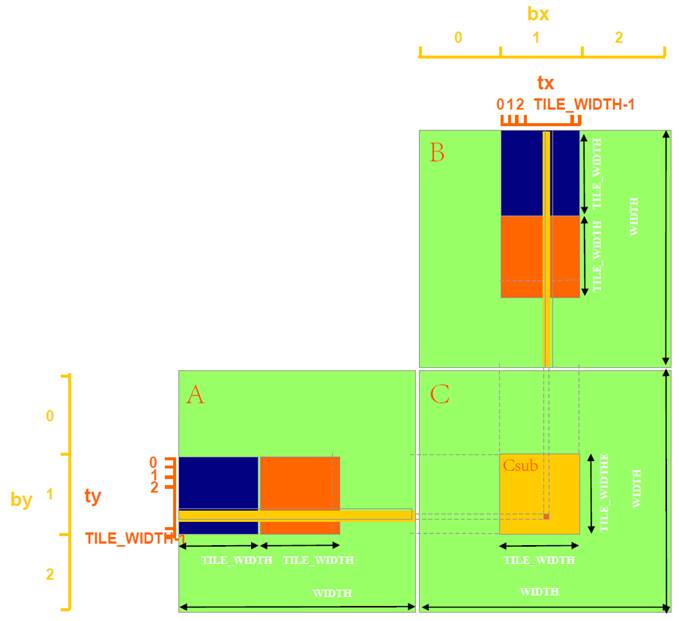
CUDA并行分块算法
每个线程块计算一个大小为BLOCK_SIZE的方形子矩阵Csub,每个线程计算Csub子矩阵中的一个元素(假设A、B和C的大小都是BLOCK_SIZE的倍数)。
对于同一个子矩阵中的元素,由于在线程在同一个线程块内,因此可以事先将对应A、B子矩阵的元素复制到共享存储器(Shared Memory),这样,之后的多次访问就不必每次都到全局存储器中获取了。
算法基本流程:每个线程为了计算自己负责的一个C矩阵的元素,需要A的一行元素和一列元素,对应地,这个线程所在的C的子矩阵的计算需要A的一个子矩阵行和B的一个子矩阵列(如下图)。以A为例,每个线程遍历A的行时,分割为两层循环进行遍历,外层遍历对应行每个子矩阵,内层遍历子矩阵的对应行,而在同一个子矩阵内,可以由共享存储器共享子矩阵,因此,每次外循环一开始(对应一个新的子矩阵),负责该子矩阵的线程块内的线程,就一起从全局存储器的A把该子矩阵读到共享存储器,然后再开始遍历自己负责的子矩阵的行。
对于下图,第一次外循环就是访问A和B的蓝色子矩阵,对应位置线程块的线程就一起把A和B的蓝色块读到共享存储器,然后用两个蓝色块的一行和一列相乘求和,作为C的这个元素的部分和。接下来的外循环会换到红色子矩阵…不断累加这个部分和,最后得到C的这个元素值。对于C的每个元素,由每个线程并行计算。
算法分析
向量加法的计算
设n为向量长度
对于串行算法,时间复杂度为O(n)
对于并行算法,时间复杂度为O(1),这里假设每个线程计算一个分量,并且未考虑CPU与GPU的数据交换时间
矩阵分块乘法的计算
设n为矩阵高度和宽度的较大值,
对于串行算法,时间复杂度为O(n^3)
对于并行算法,时间复杂度为O(n),因为每个线程计算C矩阵的一个元素,需要访问A一行和B一列。在使用了分块方法和利用了共享存储器之后,常数因子会有所减少。这里未考虑CPU与GPU的数据交换时间。
算法源代码
向量加法的计算
//系统头文件
#include <stdlib.h>
#include <stdio.h>
#include <string.h>
#include <time.h>
#include <math.h>
//cuda头文件
#include <cuda_runtime.h>
#include "device_launch_parameters.h"
//线程块大小(只用一维)
#define BLOCK_SIZE 500
/**************************************************
* GPU上的向量加法,每一个线程块(bx, by)内线程(tx, ty)都将执行,所有变量各有一份
***************************************************/
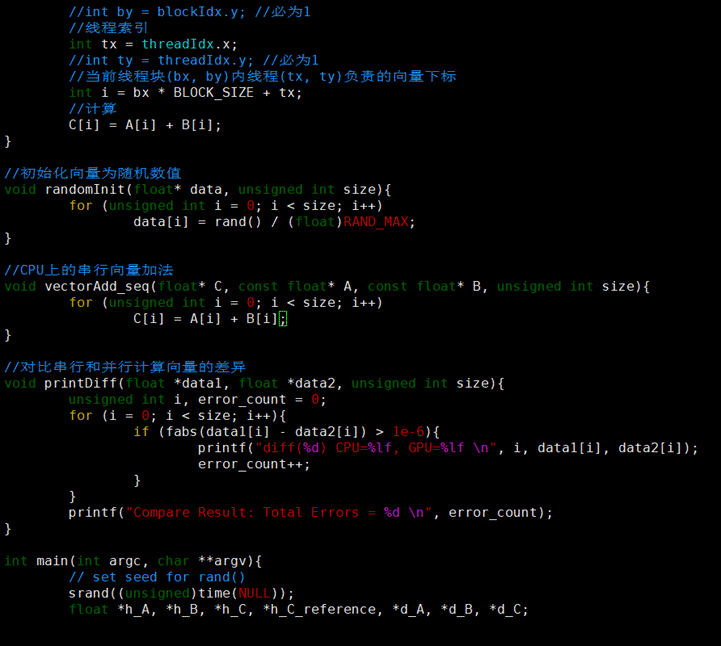
__global__ void vectorAdd(float *C, float *A, float *B){
//块索引
int bx = blockIdx.x;
//int by = blockIdx.y; //必为1
//线程索引
int tx = threadIdx.x;
//int ty = threadIdx.y; //必为1
//当前线程块(bx, by)内线程(tx, ty)负责的向量下标
int i = bx * BLOCK_SIZE + tx;
//计算
C[i] = A[i] + B[i];
}
/**************************************************
* 初始化向量为随机数值
***************************************************/
void randomInit(float* data, unsigned int size){
for (unsigned int i = 0; i < size; i++)
data[i] = rand() / (float)RAND_MAX;
}
/**************************************************
* CPU上的串行向量加法
***************************************************/
void vectorAdd_seq(float* C, const float* A, const float* B, unsigned int size){
for (unsigned int i = 0; i < size; i++)
C[i] = A[i] + B[i];
}
/**************************************************
* 对比串行和并行计算向量的差异
***************************************************/
void printDiff(float *data1, float *data2, unsigned int size){
unsigned int i, error_count = 0;
for (i = 0; i < size; i++){
if (fabs(data1[i] - data2[i]) > 1e-6){
printf("diff(%d) CPU=%lf, GPU=%lf \n", i, data1[i], data2[i]);
error_count++;
}
}
printf("Compare Result: Total Errors = %d \n", error_count);
}
/**************************************************
* 主机端主函数
***************************************************/
int main(int argc, char **argv){
// set seed for rand()
srand((unsigned)time(NULL));
float *h_A, *h_B, *h_C, *h_C_reference, *d_A, *d_B, *d_C;
clock_t t1, t2, t3, t4;
double time_gpu, time_cpu;
int sizeArray[6] = {100000, 200000, 1000000, 2000000, 10000000, 20000000};
for(int k = 0; k < 6; k++){
int size = sizeArray[k];
int mem_size = size * sizeof(float);
printf("----- Vector size: %d -----\n", size);
//在主机内存申请A,B,C向量的空间
h_A = (float*)malloc(mem_size);
h_B = (float*)malloc(mem_size);
h_C = (float*)malloc(mem_size);
//在GPU设备申请A, B, C向量的空间
cudaMalloc((void**)&d_A, mem_size);
cudaMalloc((void**)&d_B, mem_size);
cudaMalloc((void**)&d_C, mem_size);
//初始化主机内存的A, B向量
randomInit(h_A, size);
randomInit(h_B, size);
//拷贝主机内存的A, B的内容到GPU设备的A, B
cudaMemcpy(d_A, h_A, mem_size, cudaMemcpyHostToDevice);
cudaMemcpy(d_B, h_B, mem_size, cudaMemcpyHostToDevice);
//GPU内核函数的维度参数
dim3 dimBlock(BLOCK_SIZE, 1);
dim3 dimGrid(size / BLOCK_SIZE, 1);
//执行GPU内核函数
t1 = clock();
vectorAdd<<<dimGrid, dimBlock>>>(d_C, d_A, d_B);
cudaThreadSynchronize(); //CPU等待GPU运算结束
t2 = clock();
time_gpu = (double)(t2 - t1) / CLOCKS_PER_SEC;
printf("GPU Processing time: %lf s \n", time_gpu);
//从GPU设备复制结果向量C到主机内存的C
cudaMemcpy(h_C, d_C, mem_size, cudaMemcpyDeviceToHost);
//用CPU串行计算向量C,并比较差异
h_C_reference = (float*)malloc(mem_size);
t3 = clock();
vectorAdd_seq(h_C_reference, h_A, h_B, size);
t4 = clock();
time_cpu = (double)(t4 - t3) / CLOCKS_PER_SEC;
printf("CPU Processing time: %lf s \n", time_cpu);
printf("Speedup: %lf \n", time_cpu / time_gpu);
printDiff(h_C_reference, h_C, size);
//释放主机和设备申请的空间
free(h_A);
free(h_B);
free(h_C);
free(h_C_reference);
cudaFree(d_A);
cudaFree(d_B);
cudaFree(d_C);
}
system("pause");
}
矩阵分块乘法的计算
//系统头文件
#include <stdlib.h>
#include <stdio.h>
#include <string.h>
#include <time.h>
#include <math.h>
//cuda头文件
#include <cuda_runtime.h>
#include "device_launch_parameters.h"
//线程块大小(每一维大小)
#define BLOCK_SIZE 16
//矩阵规模,为线程块的整数倍
#define WA (5 * BLOCK_SIZE) // Matrix A width
#define HA (8 * BLOCK_SIZE) // Matrix A height
#define WB (12 * BLOCK_SIZE) // Matrix B width
#define HB WA // Matrix B height
#define WC WB // Matrix C width
#define HC HA // Matrix C height
//以下代码中x对应width, y对应height
/**************************************************
* 设备端:取子矩阵起始地址
***************************************************/
__device__ float *GetSubMatrixBeginAddr(float *M, int wM, int x, int y){
return M + wM * BLOCK_SIZE * y + BLOCK_SIZE * x;
}
/**************************************************
* 设备端:取子矩阵元素地址
***************************************************/
__device__ float *GetSubMatrixElementAddr(float *subM, int wSubM, int x, int y){
return subM + wSubM * y + x;
}
/**************************************************
* GPU上的矩阵分块乘法
* 每一个线程块(bx, by)内线程(tx, ty)都将执行,所有变量各有一份,除了下面的共享子矩阵为同一线程块(bx, by)内所有线程共有
***************************************************/
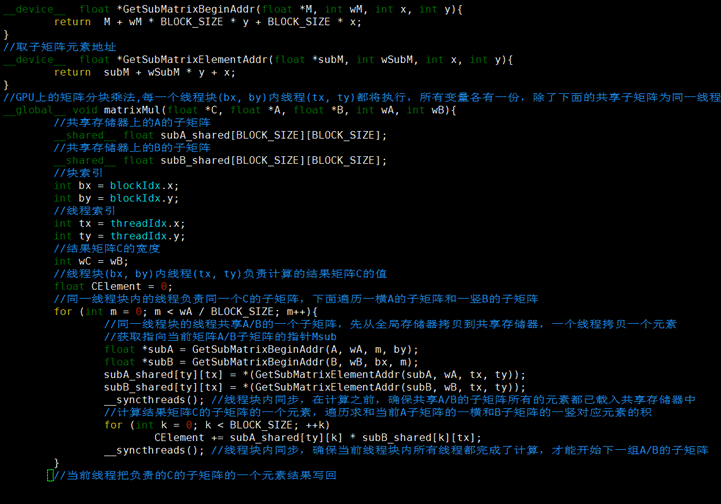
__global__ void matrixMul(float *C, float *A, float *B, int wA, int wB){
//共享存储器上的A的子矩阵
__shared__ float subA_shared[BLOCK_SIZE][BLOCK_SIZE];
//共享存储器上的B的子矩阵
__shared__ float subB_shared[BLOCK_SIZE][BLOCK_SIZE];
//块索引
int bx = blockIdx.x;
int by = blockIdx.y;
//线程索引
int tx = threadIdx.x;
int ty = threadIdx.y;
//结果矩阵C的宽度
int wC = wB;
//线程块(bx, by)内线程(tx, ty)负责计算的结果矩阵C的值
float CElement = 0;
//同一线程块内的线程负责同一个C的子矩阵,下面遍历一横A的子矩阵和一竖B的子矩阵
for (int m = 0; m < wA / BLOCK_SIZE; m++){
//同一线程块的线程共享A/B的一个子矩阵,先从全局存储器拷贝到共享存储器,一个线程拷贝一个元素
//获取指向当前矩阵A/B子矩阵的指针Msub
float *subA = GetSubMatrixBeginAddr(A, wA, m, by);
float *subB = GetSubMatrixBeginAddr(B, wB, bx, m);
subA_shared[ty][tx] = *(GetSubMatrixElementAddr(subA, wA, tx, ty));
subB_shared[ty][tx] = *(GetSubMatrixElementAddr(subB, wB, tx, ty));
__syncthreads(); //线程块内同步,在计算之前,确保共享A/B的子矩阵所有的元素都已载入共享存储器中
//计算结果矩阵C的子矩阵的一个元素,遍历求和当前A子矩阵的一横和B子矩阵的一竖对应元素的积
for (int k = 0; k < BLOCK_SIZE; ++k)
CElement += subA_shared[ty][k] * subB_shared[k][tx];
__syncthreads(); //线程块内同步,确保当前线程块内所有线程都完成了计算,才能开始下一组A/B的子矩阵
}
//当前线程把负责的C的子矩阵的一个元素结果写回
float *subC = GetSubMatrixBeginAddr(C, wC, bx, by);
*(GetSubMatrixElementAddr(subC, wC, tx, ty)) = CElement;
}
/**************************************************
* 初始化矩阵为随机数值
***************************************************/
void randomInit(float* data, int size)
{
for (int i = 0; i < size; ++i)
data[i] = rand() / (float)RAND_MAX;
}
/**************************************************
* CPU上的串行矩阵乘法
***************************************************/
void matrixMul_seq(float* C, const float* A, const float* B, unsigned int hA, unsigned int wA, unsigned int wB){
for (unsigned int i = 0; i < hA; ++i)
for (unsigned int j = 0; j < wB; ++j){
double sum = 0;
for (unsigned int k = 0; k < wA; ++k)
sum += A[i * wA + k] * B[k * wB + j];
C[i * wB + j] = (float)sum;
}
}
/**************************************************
* 对比串行和并行计算矩阵的差异
***************************************************/
void printDiff(float *data1, float *data2, int width, int height){
int i, j, k, error_count = 0;
for (j = 0; j < height; j++){
for (i = 0; i < width; i++){
k = j * width + i;
if (fabs(data1[k] - data2[k]) > 1e-4){
printf("diff(%d, %d) CPU=%4.4f, GPU=%4.4f \n", i, j, data1[k], data2[k]);
error_count++;
}
}
}
printf("Compare Result: Total Errors = %d \n", error_count);
}
/**************************************************
* 主机端主函数
***************************************************/
int main(int argc, char **argv){
// set seed for rand()
srand((unsigned)time(NULL));
//在主机内存申请A,B,C矩阵的空间
unsigned int size_A = WA * HA;
unsigned int mem_size_A = sizeof(float) * size_A;
float* h_A = (float*)malloc(mem_size_A);
unsigned int size_B = WB * HB;
unsigned int mem_size_B = sizeof(float)* size_B;
float* h_B = (float*)malloc(mem_size_B);
unsigned int size_C = WC * HC;
unsigned int mem_size_C = sizeof(float)* size_C;
float* h_C = (float*)malloc(mem_size_C);
//在GPU设备申请A, B, C矩阵的空间
float* d_A;
cudaMalloc((void**)&d_A, mem_size_A);
float* d_B;
cudaMalloc((void**)&d_B, mem_size_B);
float* d_C;
cudaMalloc((void**)&d_C, mem_size_C);
//初始化主机内存的A, B矩阵
randomInit(h_A, size_A);
randomInit(h_B, size_B);
//拷贝主机内存的A, B的内容到GPU设备的A, B
cudaMemcpy(d_A, h_A, mem_size_A, cudaMemcpyHostToDevice);
cudaMemcpy(d_B, h_B, mem_size_B, cudaMemcpyHostToDevice);
//GPU内核函数的维度参数
dim3 dimBlock(BLOCK_SIZE, BLOCK_SIZE);
dim3 dimGrid(WC / BLOCK_SIZE, HC / BLOCK_SIZE);
//执行GPU内核函数
clock_t t1 = clock();
matrixMul<<<dimGrid, dimBlock>>>(d_C, d_A, d_B, WA, WB);
cudaThreadSynchronize(); //CPU等待GPU运算结束
clock_t t2 = clock();
double time_gpu = (double)(t2 - t1) / CLOCKS_PER_SEC;
printf("GPU Processing time: %lf s \n", time_gpu);
//从GPU设备复制结果矩阵C到主机内存的C
cudaMemcpy(h_C, d_C, mem_size_C, cudaMemcpyDeviceToHost);
//用CPU串行计算矩阵C,并比较差异
float* hC_reference = (float*)malloc(mem_size_C);
clock_t t3 = clock();
matrixMul_seq(hC_reference, h_A, h_B, HA, WA, WB);
clock_t t4 = clock();
double time_cpu = (double)(t4 - t3) / CLOCKS_PER_SEC;
printf("CPU Processing time: %lf s \n", time_cpu);
printf("Speedup: %lf \n", time_cpu / time_gpu);
printDiff(hC_reference, h_C, WC, HC);
//释放主机和设备申请的空间
free(h_A);
free(h_B);
free(h_C);
free(hC_reference);
cudaFree(d_A);
cudaFree(d_B);
cudaFree(d_C);
system("pause");
}
结果
登录集群,建立个人文件夹,建立代码文件和任务文件
向量加法的计算
使用vim编辑pbs文件,填写任务相关信息
使用vim编辑vec_add.cu文件,将事先写好的代码粘贴进去
提交任务,稍等几秒,得到编译结果和运行结果
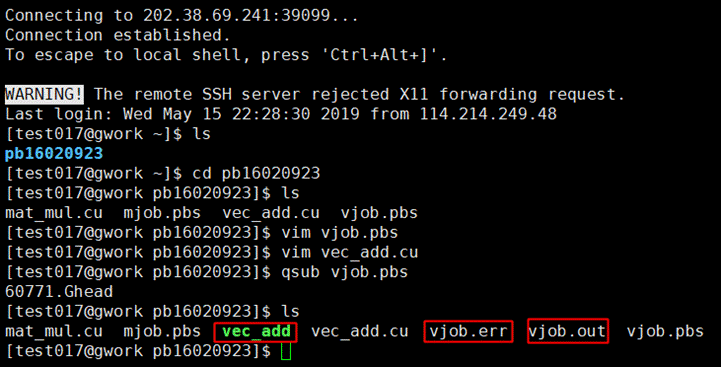
查看运行结果
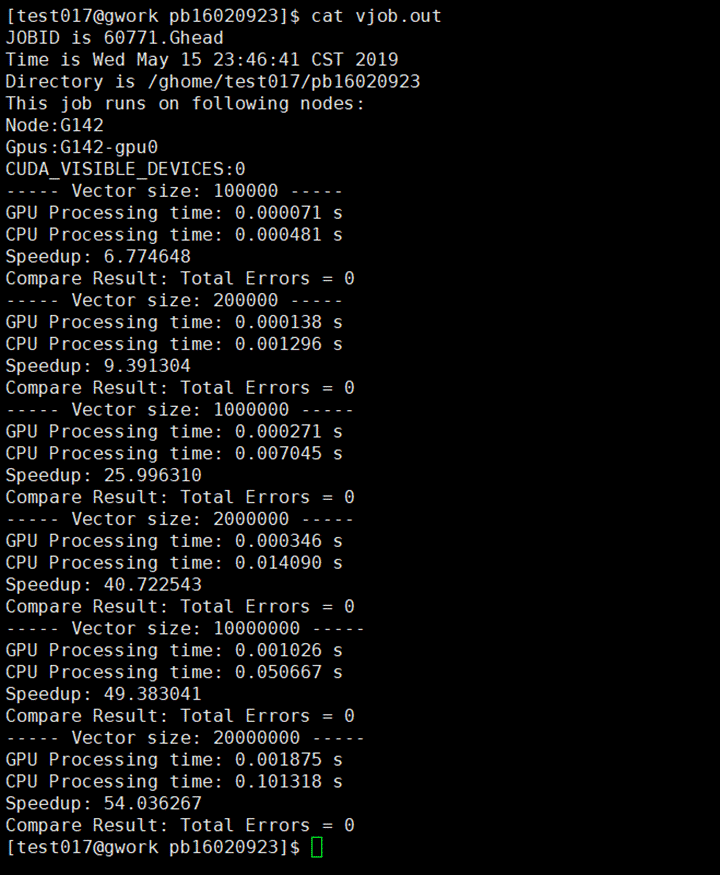
可见不同规模的向量加法得到的加速比不同。在一定范围内,规模越大,加速比越大
矩阵分块乘法的计算
使用vim编辑pbs文件,填写任务相关信息
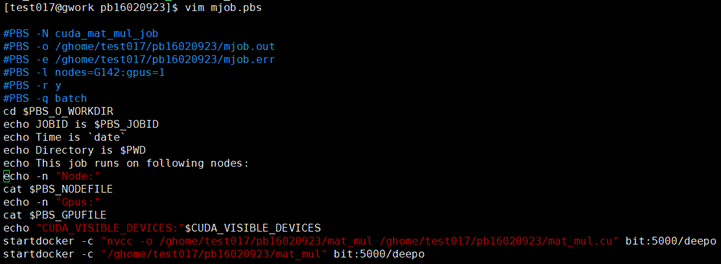
使用vim编辑mat_mul.cu文件,将事先写好的代码粘贴进去
这里预置的矩阵规模为A(5个BLOCK_SIZE宽,8个BLOCK_SIZE高),B(8个BLOCK_SIZE宽,13个BLOCK_SIZE高),BLOCK_SIZE = 16
提交任务,稍等几秒,得到编译结果和运行结果
查看运行结果
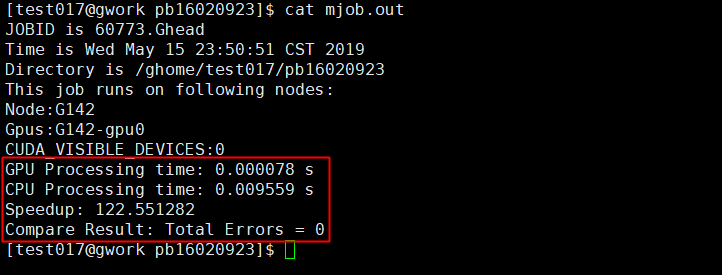
加速比为122.55,加速效果明显
再进行一次实验,
这次矩阵规模为A(15个BLOCK_SIZE宽,18个BLOCK_SIZE高),B(18个BLOCK_SIZE宽,22个BLOCK_SIZE高) ,BLOCK_SIZE = 16
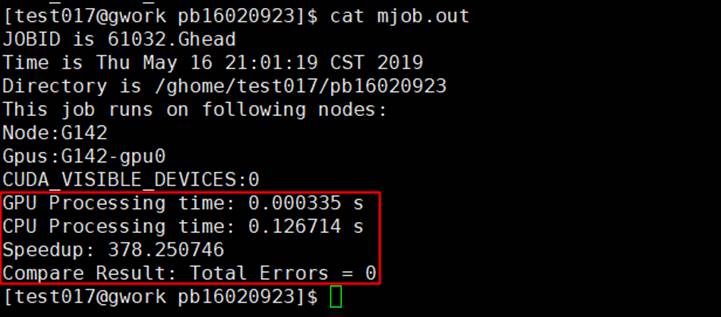
加速比为378.25,加速效果更明显
可见在一定范围内,矩阵规模越大,加速比越大